The brief:
- Your company sells dinosaur toys
- Different vendors value these dinosaurs toys at different prices depending on the market data on dinosaur toys they’ve aggregated
- Your company experienced hypergrowth1, so many teams have written their own code to call different vendors
- You’re tasked with designing a single endpoint that teams can call to retrieve valuations for a dinosaur toy from as many or as few vendors as they desire. This endpoint has to be fast.
The last point is interesing and makes GraphQL a sensible choice. GraphQL is ideal at providing exactly what you ask for, and not fetching data you didn’t ask for, or forcing you to make multiple HTTP calls to fetch more data.
With that in mind, we’re going to go with a serverless setup of:
- AWS AppSync to manage a GraphQL API which teams can call for a dinosaur toy value
- Running the code (Python) to call vendors on AWS Lambda.
For now, we can ignore details like persisting the data from vendors in a data warehouse 2, or caching data in a highly available data store 3.

The schema
We can encapsulate this all in a single GraphQL query. Why not have multiple queries? It one less thing to manage. Besides, this all groups logically into one domain: get me dinosaur toy prices.
Consider this GraphQL schema:
|
|
How do we call the backend?
Should we have a single Lambda that handles the whole query or multiple Lambdas?
If we have a single Lambda then:
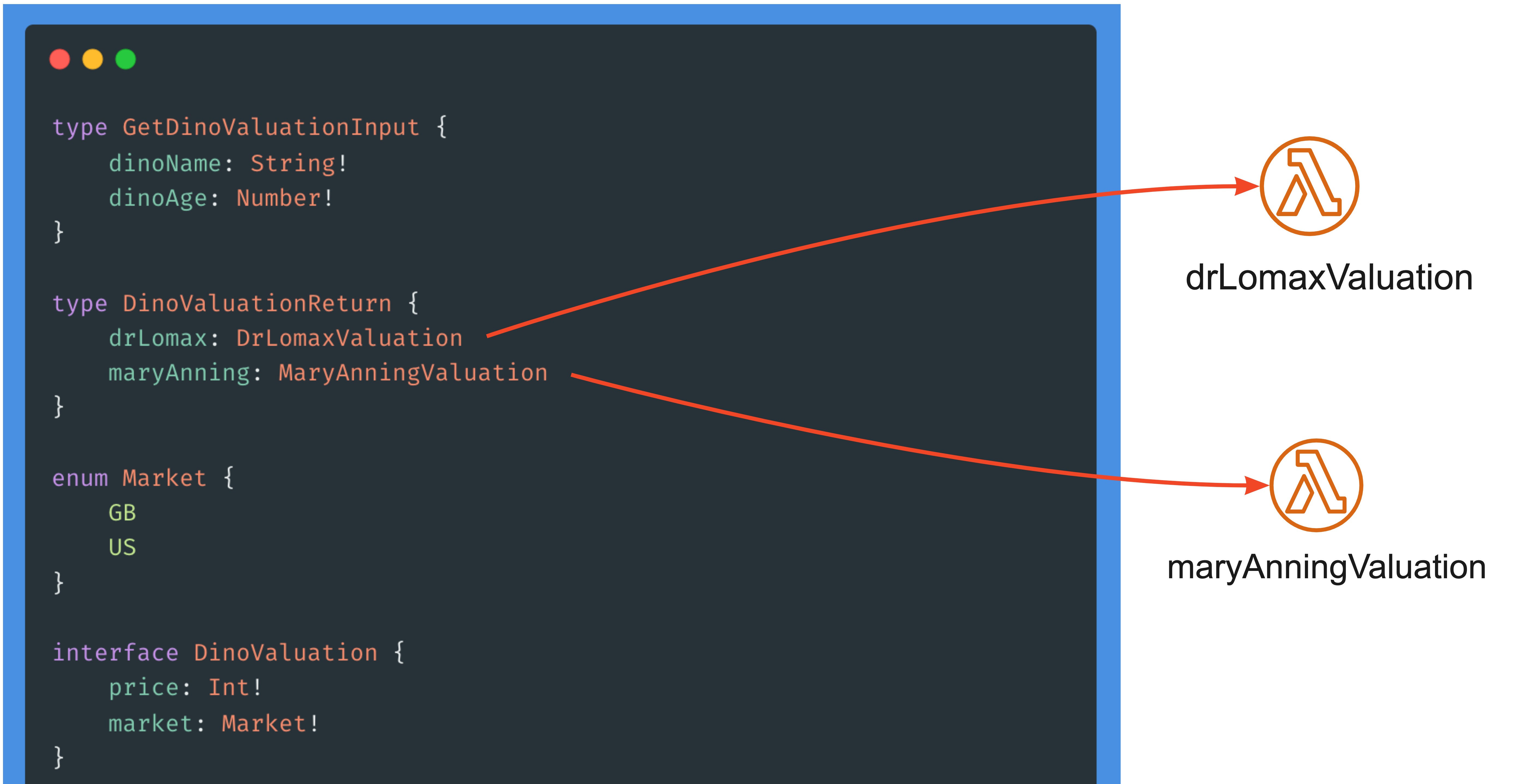
- There’s no easy way to communicate from AppSync to the Lambda which fields (
drLomaxormaryAnning) have been requested. We’ll have to query all dinosaur toy vendors and then AppSync will handle returning only those which were requested. Calling all vendors each time could be expensive. - To make the API fast and responsive, we’ll have to implement concurrency with threading or asynchronous Python. The former can be tricky to manage with race conditions, and few people are experienced at developing with the latter.
Contrast that with using multiple Lambdas per vendor:
- We only invoke the Lambdas that are requested: one Lambda to resolve the type
DrLomaxValuation; one to resolve the typeMaryAnningValuation - We ignore threading, concurrency and let AWS invoke Lambdas in parallel as they’re requested. Lambdas as super cheap. This is great: we get to focus on the business logic rather than on technical details.
The default option with AWS AppSync is to write Apache Velocity Templating Language (VTL) to take your GraphQL and send it to a Lambda. I think VTL sucks. It’s yet another templating language to learn, and there’s no clear way of testing the VTL you write.
Here’s where direct Lambda resolvers step in. We can send GraphQL queries directly to a Lambda, and handle everything in the Lambda.
From a code point of view this is simple!
|
|
Obviously these aren’t calling any external valuators for now, we’ll take that as a trivial implementation detail. To finish, we can write infrastructure-as-code to have AppSync resolve the types to the relevant Lambdas. See Addendum.
Done! Well, not quite. This doesn’t actually work, because while there’s resolvers for each sub-field, there’s no resolver for the top level Query type.
Adding a top level Lambda
Conspicuously missing from the AWS documentation on direct Lambda resolvers is an example of a top level Lambda that resolves the Query and routes from that resolver to other Lambdas that handle nested sub-types.
If we resolve just the Query then we can pass in a top level parent ID to the Lambdas that resolve the fields nested within the Query. This is great for reporting downstream: you have a single ID that captures the request, invocation, and return of all data when your API is called.
We can write
|
|
and we modify the other nested sub-handlers to consume event["source"]["input"] instead of event["arguments"]["input"].
Our new architecture diagram looks like:
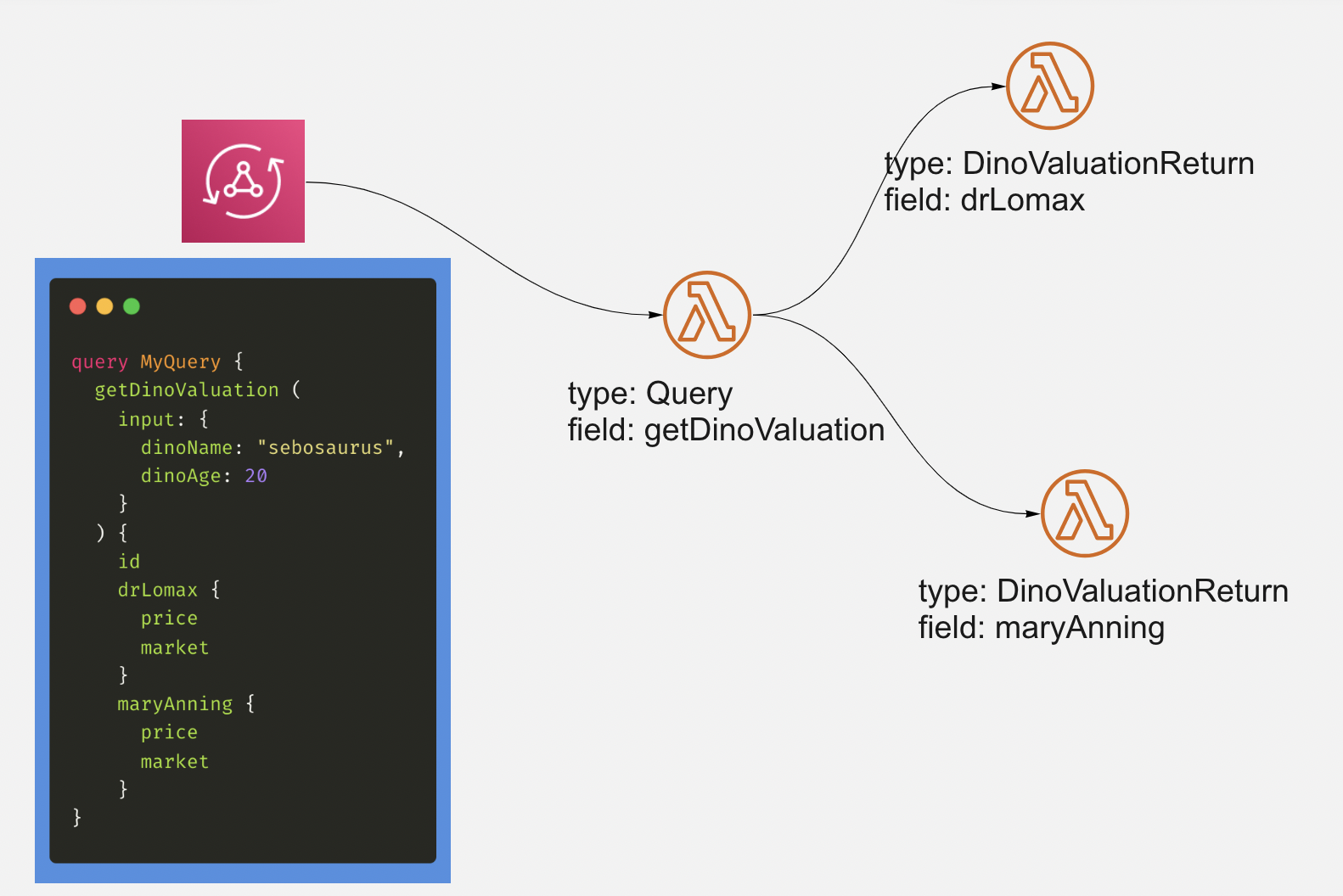
And there you have it, a free-unless-used serverless GraphQL API with virtually unlimited scaling which fetches only as much data as requested (and only calls as many vendors as requested), and where you don’t have to worry about any of the normal technical details of handling I/O bound tasks like calling multiple HTTP endpoints.
Addendum
A. Other documentation
I was prompted to write this piece because the existing documentation on this isn’t quite clear.
For example, AWS has some documentation on this already but they resolve the top-level Query AND one of its nested sub-types in a single resolver. This means one Lambda is a ‘special’ Lambda, with a different setup to the others, and prevents you from having a top-level parent ID passed to each Lambda.
B. AWS Lambda Powertools
AWS Lambda Powertools are awesome but I don’t think we can use them in our setup. Unfortunately the resolver only routes the input arguments, so when we pass data from a top level source down to a lower level, we’ll lose all our arguments.
That’s annoying, because then we could have just one Lambda for all our resolves that implements all our business logic. If anyone knows of a way around this, please let me know!
C. Terraform
The Terraform code for the direct Lambda resolvers as data sources and resolvers for AppSync can be found here.
The following are not included since they are generic:
- Terraform code for AppSync setup, API Gateway, Route53, etc.
serverless.ymlconfiguration to setup the Lambdas